Agent, environment and reward
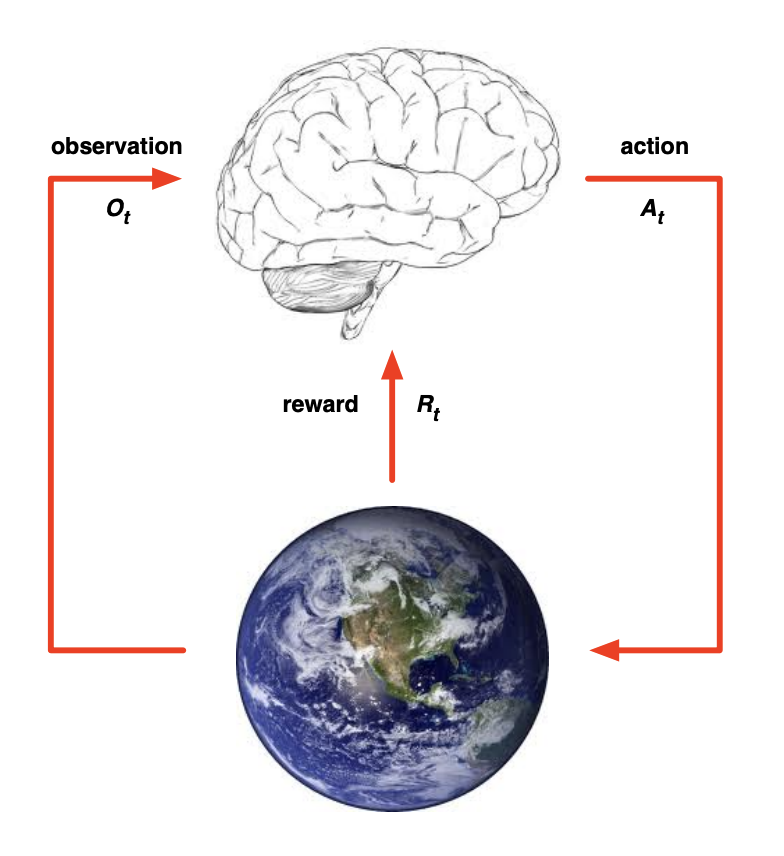
Agent: Our mind, soul and body.
Environment: The external world.
Reward: food, water, money, status, fulfillment, joy…
The mind, soul and body takes actions, interacts with the external world and collect rewards. The reward could be either be positive – food, water, money…, or negative – punishment.
Life goal is to maximize reward
The agent’s goal is to maximize reward, so as human being.
In the RL problem, the goal is clear, measurable. In life, most of the time the goal is unclear, unmeasurable. Or, there are multiple weighted goals.
How one weights their different life goals, is called value system.
Future reward is discounted
The discounting factor \lambda is between 0 and 1. When it is set to 0, it is the most shortsighted trait that only care about the immediate reward. (Drugs, sexual abuse, food abuse, crime…) When it is set to 1, it is the most longsighted trait that cares the immediate reward and future rewards at a same weight.
Technically, \lambda can be greater than 1, which means we don’t care much less about the immediate reward than the future reward. In some religions, followers suffer in the current life in return for a better afterlife.
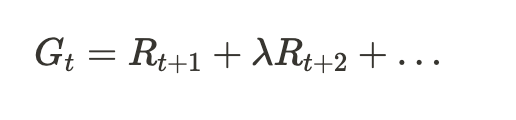
The way you show up is a Markov state
The way you show up now contains all your past experiences. Your trauma, achievements, education, family relationships… shapes who you are.
How you behave now, contains all the information of your past states.
A hero is not judged by their origins – 英雄不问出处
Building models to simulate the environment
We are building models, based on our experience, to understand how the environment work. It works pretty well in physics, math, chemistry, but crashes in financial crises prediction, human behavior predictions, long term weather predictions.
The environment keeps changing – technology development, civilization, etc. The model also needs to keep updating.
Using experience replay to reduce variance
When finishing an episode/experience, do some reflection, to integrate what we learned from that experience.
We are not growing by experiencing. We are growing by experiencing + reflecting.
Growing means updating policy network to get more rewards in the environment.
Reward is delayed in real life
You have to learn for a while, before any significant achievement can be done. You have to go to the gym for a month, before any noticible body changes emerge.
We need faith to keep doing what we believe is right.
Variance vs Bias
Monte Carlo updates the policy function weight/value function weight after each step in each episode. It has no bias, but high variance. It learns from the knowledge, but also learns from the noise.
Temporal Difference (TD learning) updates weights of the current state, by looking 1 step ahead:
Q(s, q) = Q(s, q) + learning_rate * (r + discount_factor * argmax V(s’, q’) – V(s, q))
TD learning has bias, but low variance.
r + discount_factor * argmax V(s’, q’) – V(s, q) is the feedback. You set learning_rate for yourself.
If learning_rate is too low, you are learning too slow. If learning rate is too high, you may lose yourself, but changing yourself too quick in response to others’ feedback.
Exploration vs exploitation
It is not uncommon that the older we are, the less motivation we have to explore. It is similar to what is described in selecting epsilon in the epsilon-greedy search. As we try more and more actions, we decreasing epsilon to do more and more exploitation, to stick with the actions that give us most rewards before.
However, in a changing environment, we need to keep exploring.
Marriage is not a zero-sum game
Life is an online-reinforcement learning process.