What is data replication
Keeping a copy of the same data on multiple machines connected via a network.
The data here could either be storage or database. Data replication is different from data partition.
Why do we need data replication
- To increase availability: when one or several machines fail, the system continues to work.
- To reduce latency. Clients read/write to the replication that is geographically close to them.
- To increase read throughput. Multiple machines can serve read request.
How to do data replication
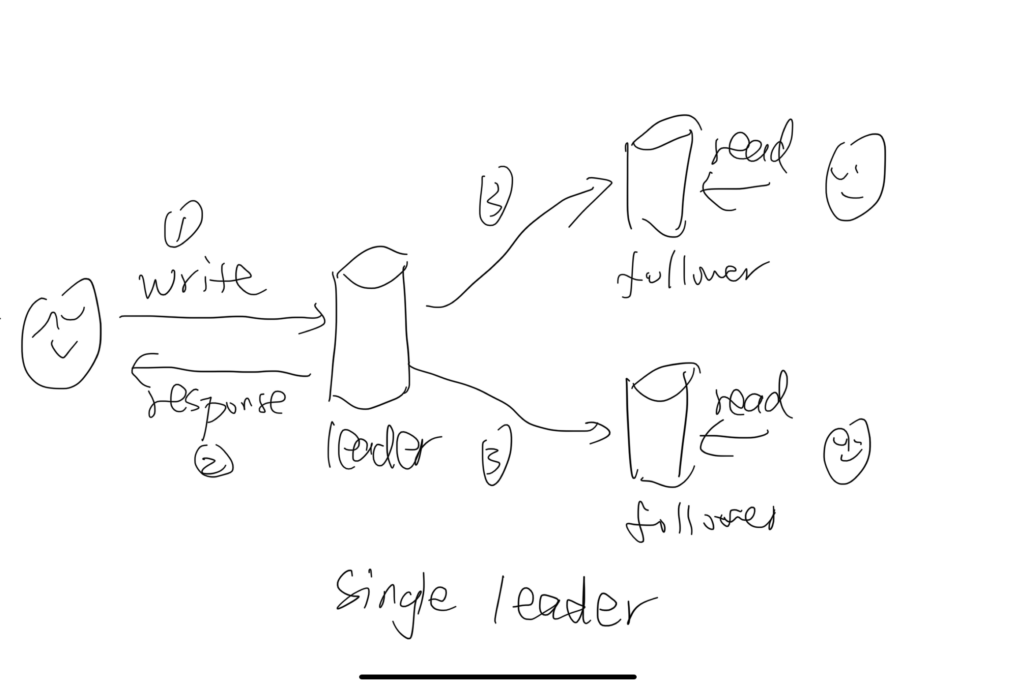
Single leader
One single machine is the leader. It accepts write and read request. When write request is received. It updates its local storage, and return to user. Then it propagates the write requests to all followers.
Multiple machines are follower. They accept read requests.
The structure is simple. It improves the read throughput.
When setting up a new follower, it first take a snapshot from the leader, copy over the data from the leader up to the snapshot. Then it requests data since the snapshot to the up-to-date timestamp from the leader.
When leader fails, which can be detected by the heartbeat signal – each machine sends “are you alive” message to leader. If leader does not respond, in 30 seconds, which is configurable, followers think leader is dead. And a new follower is elected as leader. This is achieved among all followers by a concensus protocol.
Read after write problem
After user performs a write, it must be able to see the data they write immediately. Application can keep a cache and read from that cache, or application always read from leader for data write by the user themselves.
Each user always reads data from a particular follower. Say, hash the user id, and based on the hash value, read data from a particular follower.
Multiple leaders
Multiple machines are selected as leader to accept write requests. In practice, different leaders are in different data centers.
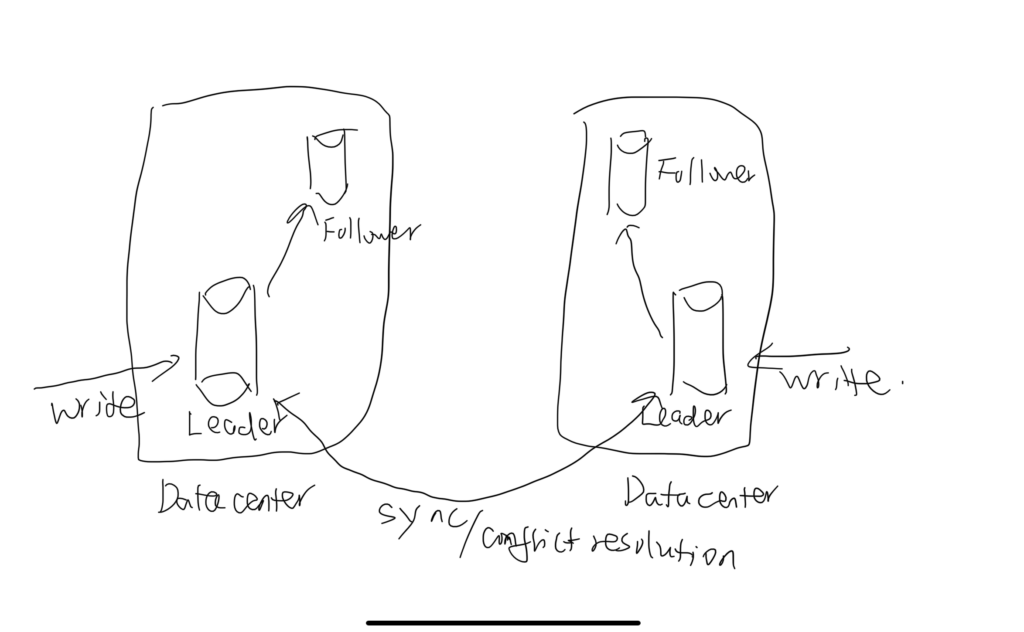
Each leader propagates write to their followers, just like in the single leader set up. And among leaders, they sync data asynchronously.
It increases both the read and write throughput, but the structure is much more complex. Leaders needs to resolve the write conflicts.
You should avoid multil-leader set up as much as possible. It is dangerous.
Use cases for multiple leaders
Collaborate editing, such as Google Docs. Each client is a leader, and they sync data to server.
Same application on different client’s devices, such as Google calendar. Your devices might be offline, and you update your Calendar on both your phone and laptop. When they are back online, they both act as leader and send data to server. There could be conflicts.
Conflict happens when the old data is A, local client 1 changes it to B, and local client 2 changes it to C. When server receives the updates from 2 clients. It needs a strategy to decide which change wins.
Conflict resolution strategies
- Give each write request a unique id (timestamp, UUID, etc). When conflict is detected on server, the write request with the highest id wins.
- Give each leader a unique ID. The leader with the highest ID always wins in conflict.
- Somehow merge the values together. (This is what Cider, the Google’s internal code management system, does. The code merging system)
- Record the conflict, preserve all information, and let application code to resolve it (This is what Cider does. The developer needs to resolve the conflicts offline themselves)
Leaderless replication
No leader nor follower. Every machine is born equal.
When write, client writes to multiple machines. The operation is only considered success when a certain number of machines are committed write. This number is W.
When read, client read from multiple machines. The operation is only considered success when a certain number of machines return the result. This number is R.
R and W is configurable. When R + W > N, where N is the total number of machines. Client is guaranteed to get the latest data from the system.
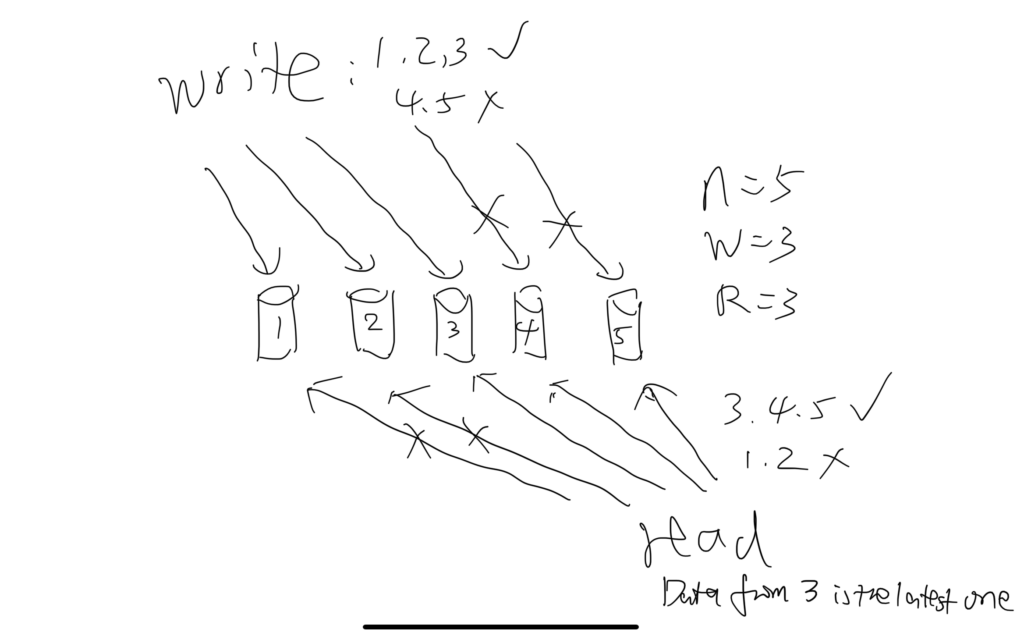
Each record read from the system is attached with the version number. When getting data from multiple machines, client preserve the data with the highest version number, and this is guaranteed to be the latest data.
When a write request is returned to client, the system keeps propagating the write request to the remaining N – W machines.
In practice, you can make W + R < N to increase availability.
Benefits of leaderless replication:
- Simple than multi-leader